 |
Discovering patterns in library website usage: a data mining approach. Anamarija Rozic-Hristovski*, Dimitar
Hristovski**, Ljupco Todorovski**/***
|
|
|
|
|
|
 |
Abstract
The websites that libraries are developing for their communities represent an important new aspect of information management. How effectively are librarians meeting the information needs of their clientele? Personalized Web access services are a demand of many users that feel overwhelmed with the information available on the Web. Building a site that satisfies this demand presupposes knowing the site as it is perceived by its users. To personalize a site according to the requirements of groups of users, users navigation patterns must be discovered and analyzed. Web usage analysis extracts knowledge from Web server log files. The Central Medical Library at the Medical Faculty, University of Ljubljana, Slovenia created its website in 1997 and since than has been actively involved in its maintenance and improvement. For the analysis of our website usage recently we have included advanced data mining methods in addition to the more traditional methods we have been using so far. Data mining is a methodology for the extraction of previously unknown patterns and knowledge from large quantities of data. In particular, we use sequence analysis to discover user navigation paths both within a single session and across different sessions by the same user. The knowledge about user behavior and interests, acquired with the data mining techniques, allows for dynamic restructuring of the website so that the users are always presented with the right content and structure. -------ooo------- Introduction The World Wide Web offers opportunities for libraries to become disseminators of information through publishing on the Internet. The websites that libraries are developing for their user communities represent an important new aspect of information management. The most effective of the library home pages appeared to be those that had a clear sense of purpose and a clear sense of users. It follows that an important aspect of the planning for a home page is to identify the likely users and to review their needs.1 Designing a website so that it readily yields its information is a difficult task. The designer must anticipate the users' needs and structure the site accordingly. Yet users may have vastly differing views of the site information, their needs may change over time, and their usage patterns may violate the designer's initial expectations. There are three factors affecting the way a user perceives and evaluates a website: content, Web page design, and overall site design. The first factor concerns the goods, services, or data offered by the site. The other factors concern the way in which the site makes content accessible and understandable to its users. It is necessary to distinguish between the design of individual pages and the overall site design, because a site is not simply a collection of pages-it is a network of related pages. The intuitive structure promotes successful exploring of website. 2 Website users differ in their navigational behaviour according to the purpose of their visit. Actual user behaviour is largely dependent on the users' needs, interests, knowledge and prejudices. Concrete knowledge about visitors' navigation patterns can prevent disorientation and help designers in placing important information exactly where the visitors look for it. Weblog analysis using data mining techniques help to understand how visitors navigate a website. Website evaluation is needed for its re-organisation. This task aims at either website personalization so as to satisfy the needs and characteristics of individual user or set of users, or at optimisation the structure of a site so as to make information more accessible and more effective to a large set of users. The Central Medical Library (CMK)
at the Medical Faculty, University of Ljubljana, Slovenia created its website
in 1997 and since than has been actively involved in its maintenance and
improvement. Recently we have introduced data mining methods for the analysis
of our website usage. In particular, we use sequence analysis to discover
user navigation paths both within a single session and across different
sessions by the same user. The knowledge about user behaviour and interests,
acquired with the data mining techniques, allows for dynamic restructuring
of the website so that the users are always presented with the right content
and structure.
Website evaluation: web usage mining Monitoring website usage is probably old as the Web itself. Early tools assisted Web site administrators in studying and balancing the Web server's load. Modern tools for web access monitoring support the computation of statistics that can serve as the basis for success analysis. Recent advances cover two domains: success measures for commercial websites and data mining techniques for analysing web usage. A way of evaluation website usage is needed before setting its personalization and continuous improvement. We can perform data mining to analyse website usage. Data mining can be defined as analysing the data in large databases to identify trends, similarities, and patterns. Data mining technologies generally use algorithms and advanced statistical models to analyse data according to rules set forth by the particular application at hand. Data mining models fall into three basic categories: classification, clustering, and associations and sequencing.3 Data mining is not query- or user driven, not it is a cumulative traffic report of hits to the site. Data mining is instead driven by the need to uncover the hidden undercurrents in the data, such as the features of the visitors generating the hits to the website. So far most analyses of websites data have involved traffic reports, of which most are geared toward providing cumulative accounts of server TCP/IP-specific browser-to-server activity. Data mining is a process that involves a set of methodologies and procedures for extracting and preparing data and then incorporating the solution into the website. In the mining of website databases work involves structured data, such as log files and databases created from registration or purchase forms.4 Several varied attempts are being made to personalise the browsing experience of website visitors, including collaborative filtering and the aggregate pooling of cookies through ad networks. How can data mining answer website usage questions? There is increasing amount of business and trade literature that answers these questions. As library literature on data mining applications is very scarce librarians can learn from successful marketing solutions. However, some effort is needed to use the web mining solutions designed with business application in mind in library environment. A site can be evaluated using questionnaires, but this is a very time consuming approach. We would like to evaluate a site based on the data automatically recorded on it. Each site is electronically administered by a Web server, which logs all activities that take place in it in a file, the Web server log. All traces left by Web users are stored in this log. From this log, we can extract information that indirectly reflects the sites quality by applying data mining techniques. Spiliopoulou5 has shown that conventional mining algorithms are not appropriate for the discovery of web usage patterns, because modelling navigation patterns as associations or sequences oversimplifies the problem and statistical measures like frequency of access are too simple for navigation pattern discovery. The miners MiDAS6 and WUM7 have been designed especially for the discovery of navigation patterns in the Web. WUM focuses on depicting and exploiting the navigation behaviour of users group. 1. Website success The first efforts in modelling the success of a web site are related to the quality of its pages. Sullivan8 distinguishes among quality of service, such as response time, quality of navigation and accessibility of a page. However these measures are difficult to quantify at the level of a whole site, especially because the importance of each page varies and is often context-sensitive. Concept hierarchies are used in market-basket analysis to generalise individual products into more abstract concepts. This enables the discovery of correlations that are manifested frequently enough among the abstract concepts although they occur rarely among individual products. For the measurement of success towards the site's goal the work of Spiliopoulou10 proposes a different type of concept hierarchy which model and abstract the site's services that generate the URLs and fill them with contents. By mapping URLs into abstract service-based concepts, the site's pages are mapped into action and target pages at different levels of abstraction and observe the behaviour of its users accessing these pages. Berthon et al.9 stress the need for measuring the success of a site with respect to the objective goals. They propose two measures of the site success, the contact efficiency and conversion efficiency. The first measure return the fraction of users that spent at least a user-defined minimum amount of time exploring the site. The second measure returns the ratio of users that after exploring the site also purchase something. The success of the site is defined as its efficiency in "converting" visitors into customers and can be measured without the involvement of users. The study of Spiliopoulou10 takes aim at measuring and improving the site's success. To model success in the context of the business objectives of website owner it undertakes three steps. It fist models contents of a site according to concepts reflecting its objective goals. After that it categorises the site's users with respect to their activities in pursuing those goals. Finally, the site success is defined as the efficiency of its components in helping users to achieve the site's goals. When measuring the success of a website, the analyst must specify the site's goal towards which success should be measured. To make the site's goal explicit for the analysis of user behaviour, the site's pages in terms of their function in pursuing this goal are characterised. An "action page" is defines as a page whose invocation indicate that the user is pursuing the site goal. A "target page" is defined as a page whose invocation indicates that the user has achieved the site's goal. A sequence of activities performed by the visitor and observed by analyst as a single work unit is termed a "session". An "active session" is a session containing at least one activities towards fulfilling the site's goal. According to the previous definition of action pages, active sessions are those containing an access to at least one action page. A "customer session" is a session in which the user has achieved the site's goal. Using the concepts of action page and active session as a basis the study defines "contact efficiency of an action page" as a ratio of sessions containing this page to all sessions in the log. The knowledge discovery process for success analysis is typically modelled as a series of steps: specification of problem, gathering and preparation of data, analysis of the data mining techniques, evaluation of results, interpretation of results and action according to strategic decisions. 2. Navigation pattern discovery The previously mentioned efficiency measures estimate the efficiency of the individual pages, which is indirectly reflected in the behaviour of the site's visitors. This behaviour is registered in the form of consecutive URL requests. The log of individual requests is transformed into a log of sessions, from which navigation patterns should be extracted. A "session" is a sequence of consecutive URL requests performed by the same visitor. The boundaries of a session can be specified either by duration or by content. The boundaries are defined by placing an upper limit on either its total duration or on the duration of a stay on a page. The establishment of sessions is coupled with the exploitation of concept hierarchies abstracting the individual URLs of the site. A session describes the activities of one user. It is necessary to discern behavioural patterns that represent multiple users. In conventional sequence mining, navigation patterns are modelled as sequences of events that occur in order but not necessary consecutively. This seems not sufficient to model the navigational behaviour. Spiliopoulou proposes also to identify and inspect the frequent and less frequent paths used to reach them.5 3. Evaluating website success In the end there is a question which patterns should be discovered to evaluate website success. The notion of success is related to the business strategy of its owner. Similarly to other areas of data mining, the knowledge discovery process requires the participation of the human expert, that is the website owner. The study of Spiliopoulou10 proposes multiple phases to guide the interactive mining process. They involve measurement of the contact efficiency of each action page and identification of action pages that are rarely reached. Conversion efficiency is measured for active sessions only. Discovering patterns containing pages with low conversion efficiency is needed for redesign of these pages to better serve the purpose of the site. A comparative analysis between customer sessions and non-customer sessions help to identify navigational particularities of each group. 4. Gathering and preparing web data The main sources for website data are log files, cookies, and forms. Web server automatically record the following information about a request in log files: client host Internet Protocol (IP) address, time stamp, method, URL address of requested document, HTTP version, return code, bytes transferred, referrer page URL, and agent. However, it is generally difficult to perform user-oriented data mining directly on the server log files because they tend to be ambiguous and incomplete. Due to use of proxy servers by Internet Service Providers and firewalls, true client addresses are not available to the Web server. Instead of various distinct client IPs, the same proxy server or firewall IP will be recorded in the server log files, representing requests of different users. Some Web pages are generally cached by local clients or various proxy servers in order to reduce network traffic. As a result log records will be missing for the corresponding accesses to the cached Web pages, resulting in incomplete log.11 To solve the problem of proxy servers or firewalls masking user IPs, it generally requires either user registrations or log-ins or the employment of cookies between the Web server and client browsers. With log-ins or cookies, a Web server can identify distinct requests made by individual user. Cookies dispensed from the server can track browser visits and pages viewed and can provide some insights into how often a visitor has been to your site and what sections they wander into. Cookies are special HTTP headers that servers pass to a browser. They reside in small text files on a browser's hard disk. You can find the cookie value in the last field of the extended log format file. They are used as counters and unique identification values that tell retailers who is a first-time visitor and where returning visitors have been within a site. By far the most effective method of gathering Web site visitor and customer information is via registration and purchase forms. Forms can provide important personal information about visitors, such as gender, age, and ZIP code. Form submissions can launch a CGI program that returns a response to the Web site visitor. Forms are simple browser-to-server mechanisms that can lead to a complex array of customer interaction from which relationships can evolve. These customer relationships can evolve into direct feedback systems through which consumers can communicate with a retailer and servers can continue to gather information from browsers.12 3. CMK website evaluation For the CMK website evaluation we used the WUM7 miner and the data mining methodology it supports. The CMK website (http://www.mf.uni-lj.si/cmk/) aim is to serve as a library guide to its resources and services. The planned content of the website has influenced the approach to its structure. The CMK website is built as an information entity embedded in an uniform graphic design that encompasses three levels of menus, two levels of headers, footer and background. It is built up from two frames. There is possible to choose between eight sub-menus that provide some key information needed for effective use of CMK and access to information resources. The sub-menus are General Information, Information Resources, Internet Resources, Services, CMK Activities, Request Forms, What's New and Messages to CMK. Users can explore the website by browsing through menus until they find the desired text page or link or by searching. The CMK home page has eleven hot link buttons that enable direct access to the most important items on the website and connection to the Medical Faculty and University of Ljubljana home pages. The CMK website is under continuous development, especially its digital library. The number of full text journals and databases increases permanently. New educational programs and services are added on regular basis. The new content demands for dynamic website maintaining and restructuring. Improving the success of the website is the aim we would like to follow up. For this purpose we propose adaptation of methodology explored in previous sections for the library environment. 1. Methods One of the first things to do when evaluating a website is to define the goal of the site. In other words, it should be specified which web user behaviour is considered a success and which not. Most of the data mining tools in general and also most of those used for web mining were created with business use in mind. Thus, by these tools, there are two categories of web site users: customers and non-customers. And the behaviour of the web site users is considered a success when they buy a product online. So, one of the major challenges in applying data mining tools when analysing library web sites is to find equivalent concepts in the library environment for the business concepts mentioned above. In the case of the CMK website, to improve the success of the site, we selected reading text pages and using hyperlinks as the goal for the analysis. Text pages describe library services, information resources, circulation policy and bring news. Hyperlinks can be of internal or external nature. That means navigation can be limited to the particular website or is extended on the other sites of interest. An action page is a query strategy and a first page of each sub-menu. Query strategy requires text input. The first page brings subject categories covered by a sub-menu. A target page is a text-page describing library services. A target page is also a link to external resources, like full text electronic journals, online databases and relevant websites. Library websites are often of the reference nature by providing lists of hyperlinks to electronic journals, databases and other websites, that are available on external Web servers. For that reason accesses to the target pages are not included in the local Web log file and are excluded from the computation of conversion efficiency. We define that an active session is converted into customer one if the stay on the target page exceeded 5 minutes. This time enables visitors to inspect the object. We loaded the web server logs into
the WUM miner using the following options.
After loading the web log files we established web user sessions. We considered a session finished when there was no request for another web page within 30 minutes of the last page requested. 2. Results and discussion The WUM miner can produce some typical web usage reports similar to other web log analysis tools. However, the distinctive feature of WUM is the ability to discover web usage patterns. In order to do this, WUM provides a query language which can be used to mine for usage patters according to the analyst preferences. In Figure 1 we can see a query which can be used to search for navigation paths (specified as a template t) starting at the CMK web site home page (node a) and ending at the list of electronic journals (node b). Between the starting and the end node there can be at most 5 other inner nodes (visited pages).
select t from node as a b, template # a [0;5] b as t where a.url = "/cmk/" and b.url = "/cmk/www-viri/erevije.html" and b.occurrence = 1 Figure 1. A WUM query searching
for navigation paths from the CMK home page to the page containing the
list of electronic journals.
The results of the query can be inspected and visualised in several different ways. In Figure 2 we can see the various navigation paths resulting from the above query visualised as a tree. It can be noticed that the users have used several paths to go from the CMK home page to the electronics journals page. However, the tree in Figure 2 is much more complicated then it should be. The reason for this is the implementation of the CMK web site that uses frames for organising the contents of the web pages. With frames, what appears as a single logical page is actually composed of a main page and a separate page for each frame it contains. E.g. the CMK home page consists of 3 HTML pages, the main one and 2 frames. The consequence of this is that when the user requests one page, he/she receives several pages, and this fact is recorded in the web server log file. To make the matters even worse, the order in which the pages are delivered and registered in the log file is not always the same. That is the reason there are more navigation paths in the tree then there really are. A short term solution for this problem would be to convert the web log file into a set of logical page accesses. And a longer term solution would be to redesign the site and replace the frames with tables. Although rather complicated at first glance, the tree in Figure 2 revealed some interesting and unexpected results. Because the electronic journals are one of the most sought for things in the CMK web site there is a hot link to them directly on the home page. However, we noticed that much more users took the longer indirect route through the Internet resources page. So, in this case, the users did not behave as it was supposed to by the web site designer. We plan to use discoveries such as this when redesigning our web site. There is another problem that we became aware of after doing the web site evaluation. Some of the most important links on our web site are those to external web sites such as electronic journals, databases, search engines etc. However, because these links are to external servers, they are not recorded in the web log file. Thus, we are unable to analyse the paths the users used to get to various external links and consequently to improve the access to these links. The technical workaround we plan to implement in the future is to build a locally stored page for each external link which contains auto redirection instruction for the appropriate external link. With this solution, there is an entry in the log file for every external link access, yet it is completely transparent to the web site users.
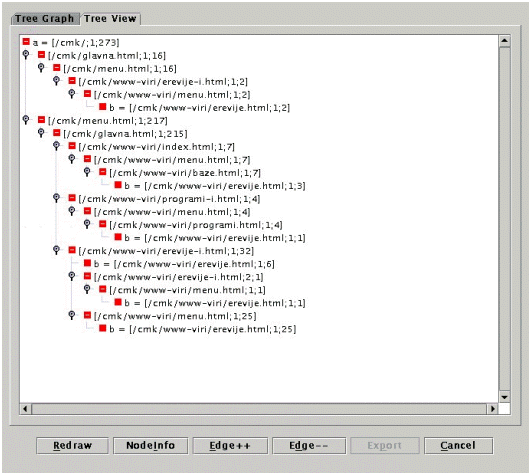 Figure 2. The navigation patterns
leading from the home page to the electronic journals page shown as a tree.
Conclusions In this paper we first gave a short overview of the methods and tools for web usage mining. Most of them have roots in business web mining. The major challenge when applying these tools for the analysis of library web sites is to find suitable equivalents for business concepts such as: customers, products and services. Then we presented the use of WUM (Web Utilisation Miner) tool to discover user navigation patterns in our own web site. We found several interesting patterns, some of which come as a surprise to the web site designer because they were unexpected to him. The discovered navigation patterns gave us a better understanding of our users and their needs. We will use this understanding to redesign and optimise our site to better serve our users. We had also some problems when analysing our site which were mostly due to the structure of the site and the use of HTML frames for the implementation of the more complex pages. We were not able to analyse the navigation patterns to the external sites because the access to these sites is not recorded in the web log. However, we have a solution to this problem which we will implement when redesigning our site. In the future we plan to personalise
our web site to the needs of a particular user. In order to do this, one
of the first things to do will be to introduce cookies and user registration
forms. It will allow us to know more about the interests of a particular
user. This knowledge, combined with navigation pattern analysis and with
some sophisticated algorithms, will give the user a personalised view of
our web site.
References 1. Laurel A. Clyde. The library as
information provider: the home page. The
|
|
|
|
|